A labour of love: 10 years of labour market research at Nesta
 www.nesta.org.uk/project-updates/a-labour-of-love-10-years-of-labour-market-research-at-nesta/
www.nesta.org.uk/project-updates/a-labour-of-love-10-years-of-labour-market-research-at-nesta/
www.nesta.org.uk/project-updates/a-labour-of-love-10-years-of-labour-market-research-at-nesta/
www.nesta.org.uk/project-updates/a-labour-of-love-10-years-of-labour-market-research-at-nesta/
Since 2015, Nesta has been researching the UK labour market via data. We’ve worked on projects to do with current skill demands and future skill requirements, skills mapping, occupation taxonomies, skill taxonomies, career pathways, and green jobs - amongst many others! Alongside this work, in 2020 we embarked on the ambitious data engineering task of scraping our own dataset of job adverts, allowing us to freely access this data in our projects as well as making our data insights more readily available externally. More about our projects can be found on our project page, and our funders and partners are given in the acknowledgements.
Following Nesta’s new strategy in 2021, we’ve been increasingly focussed on supporting our three mission areas, as well as deepening our policy work. As we focus on our missions, we will be stopping our work on labour market data. Therefore, we are ‘clocking out’ on this programme of work and want to share some reflections of what we’ve learnt and the resources we are leaving behind, as well as celebrate our work over the last decade.
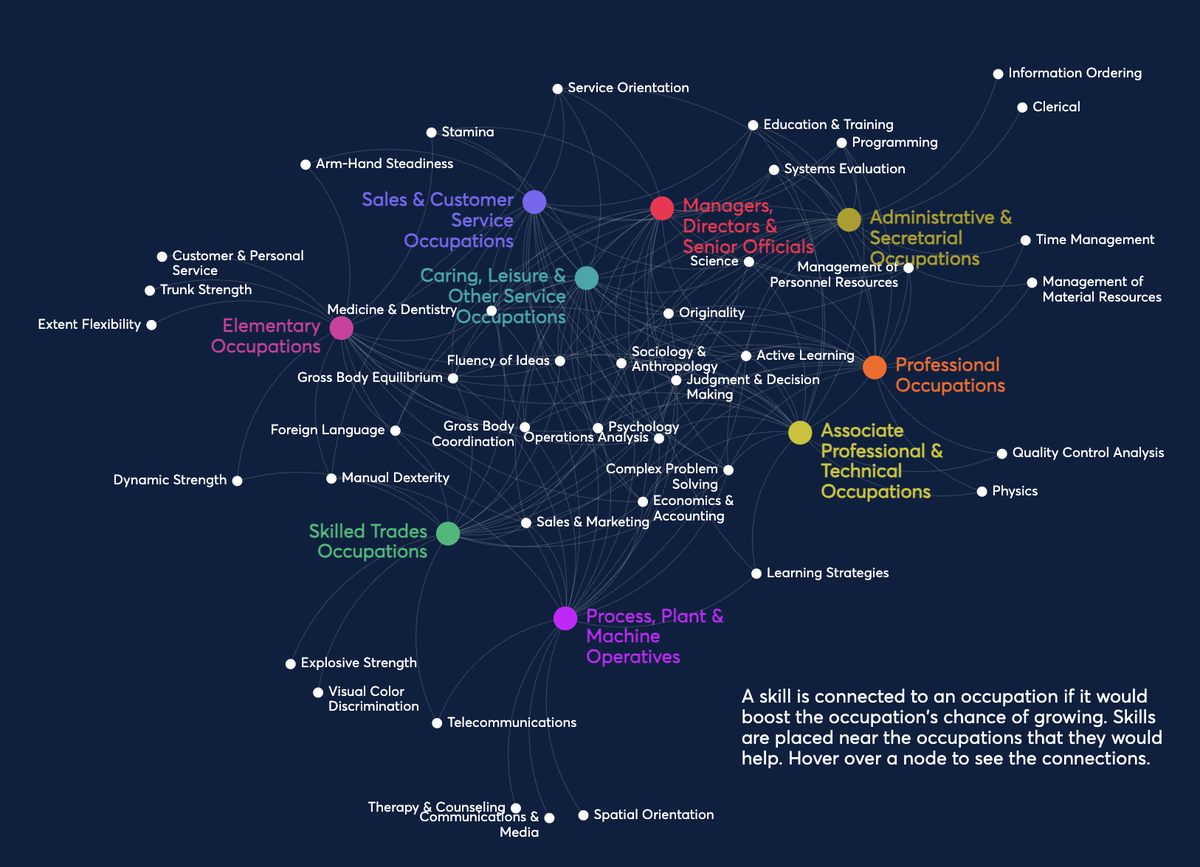
In 2015, we first realised the strength in using job advert data to monitor skill demands as a complement to the Employer Skills survey. From the start, we recognised the power in exploring this data via interactive visualisations, producing several award-winning visualisations. In 2017, we produced a skills map allowing users to input their job titles and information about the skills needed. We also created the future of UK skills visualisation, showing which occupations are likely to grow and shrink, and how skill needs might change. One finding from this was that around 10% of workers are in occupations that are likely to grow as a share of the workforce and 20% will shrink.
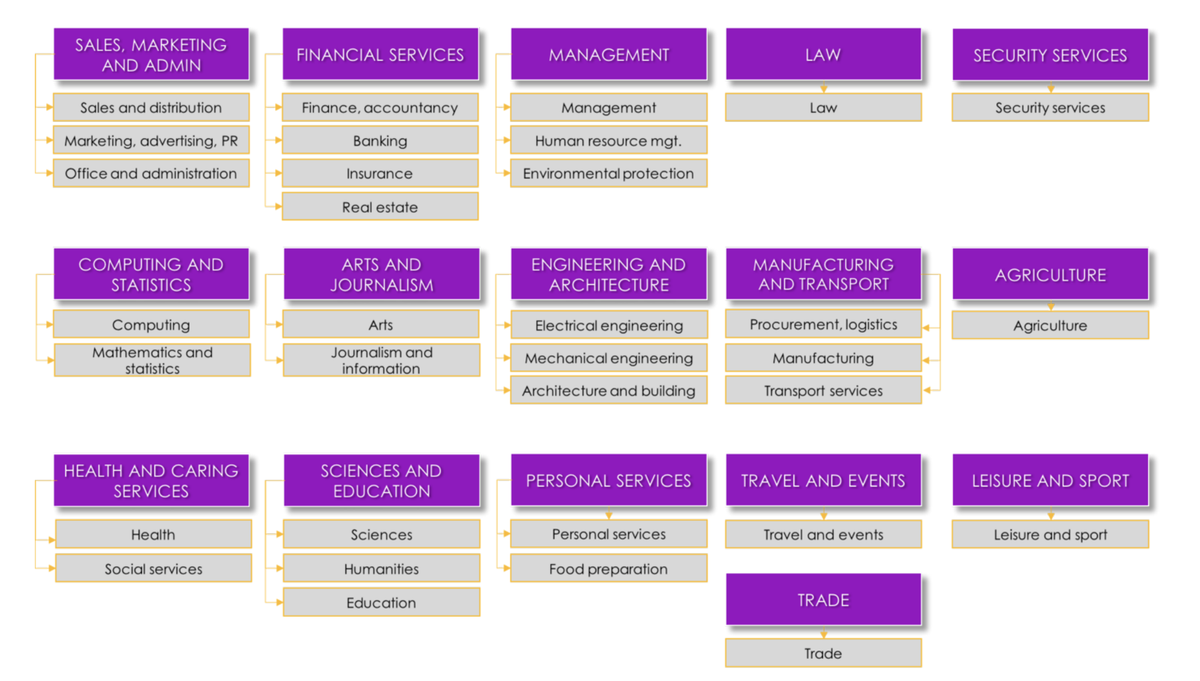
Our knowledge of analysing skills demands allowed us some insight into how certain commonly used classifications and taxonomies could be improved. For example, we recognised some limitations with the standard occupational codes (SOC) and sought to create a new occupation taxonomy to help group-skill specialisms more appropriately, writing the findings up in a 2018 discussion paper.
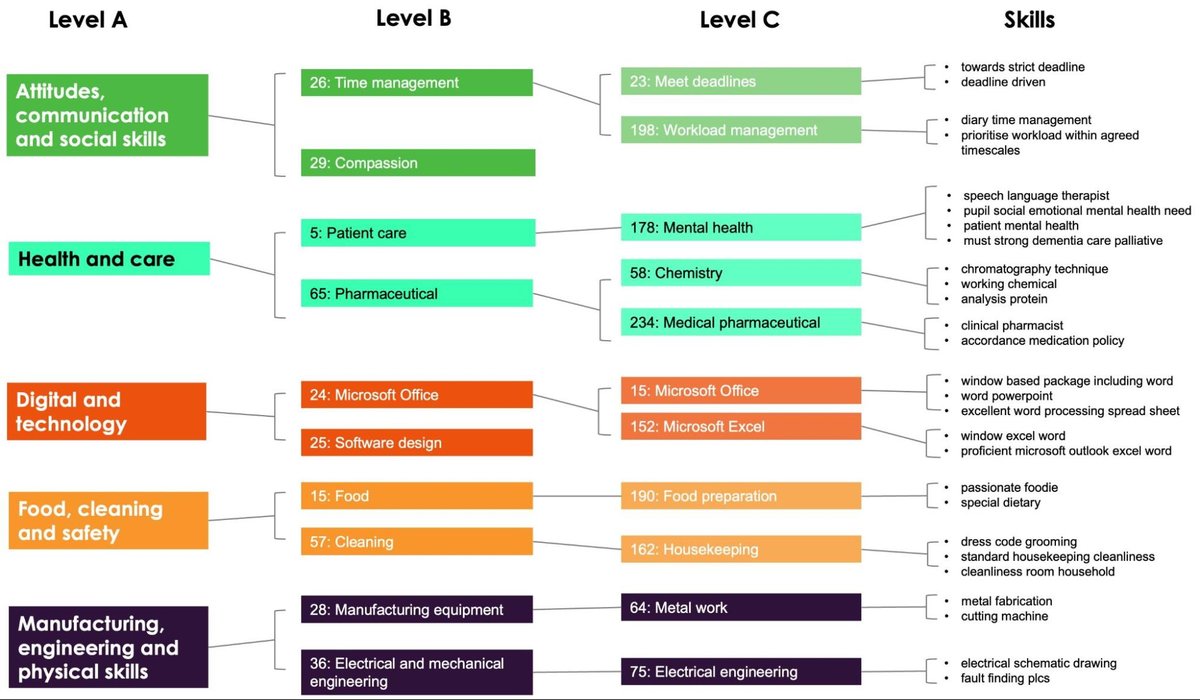
Expert-derived skills taxonomies such as European Skills/Competences, Qualifications and Occupations (ESCO) and O*NET OnLine are well recognised and used; however they need to be refreshed as the labour market evolves and involves some subjective decision-making. Therefore, in 2018 we created our first data-driven UK skills taxonomy using data from Burning Glass, and updated this in 2021 by creating our second skills taxonomy using TextKernel data. These approaches allowed us to derive a skills taxonomy based on real UK skills being asked for in job adverts, with methods that enabled the taxonomy to be automatically updated as the skills landscape evolved. Our taxonomies have been one of the most requested resources across Nesta.
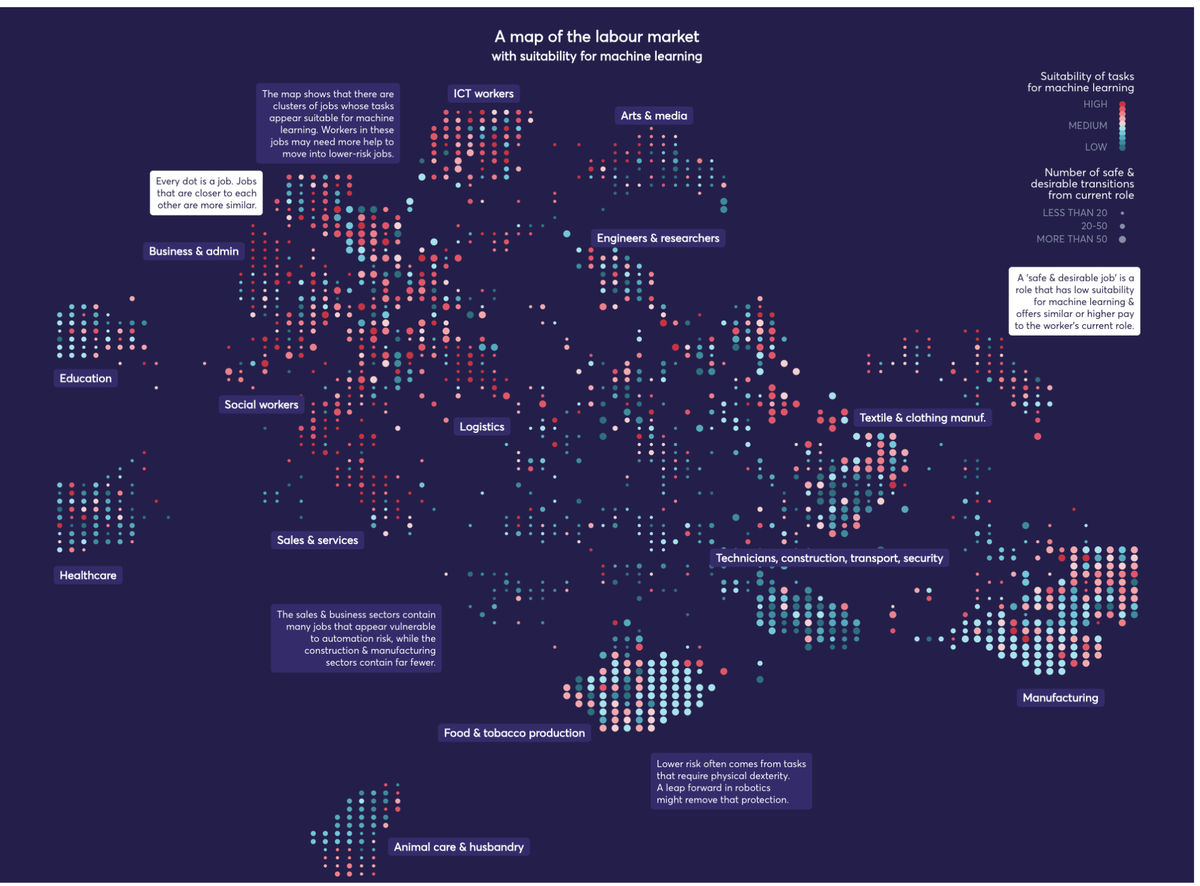
As well as broad trends across the UK labour market, we also found ourselves working on some more specific analysis pieces. This included work on the creative economy - which emphasised that creative jobs require both creative and complementary skills (eg, tech and teaching) and that this shouldn’t be overlooked in careers advice. Our work in partnership with JPMorgan Chase on identifying and providing new career pathways for occupations most at risk from automation found that the most at-risk workers were in sales, customer service and clerical roles, and more retraining would be needed to move into a lower risk occupation for these people.
Like many others, we bought our job advert datasets from Lightcast (previously Burning Glass) and TextKernel. However, in 2020 we had an increased data engineering skillset in our team, which allowed us to set about scraping our own dataset of online job adverts. After initially setting up the data scraping pipeline, which took about three months, data has been collected daily with very little need for intervention (the pipeline has only broken once in five years!). We now have over 10 million job adverts in our dataset.
We have really benefited from the fact that this dataset was freely available and could be used without restriction. Using our team's data science capabilities over the years, we’ve developed all sorts of algorithms to extract information from our job adverts, such as occupations, locations, industries hiring, skills, job quality and measures of greenness.
Developing the work of our second skills taxonomy, where we experimented with ways to extract skills from job adverts, in 2022 we started developing a specific “skills extractor” algorithm. This algorithm allows anyone to upload their own job adverts, with the skills within them being extracted and mapped to either the ESCO or the Lightcast skill taxonomies. We developed this into a python package which has been used by other researchers around the world! We created an interactive analysis blog of the most commonly-extracted skills for different professions, skills similarities across professions and regional differences in skill demands.
Building on this, in 2023 we started another project looking at green jobs. Within this, we adapted our skills extractor to pull out green skills, as well as coming up with a novel model to find company descriptions within job adverts (useful for then mapping to industry codes), and estimating occupation codes from job titles. These methods were used to extract green measures from 4 million of our job adverts and allow users to explore the insights via our Green Jobs Explorer website. One insight we found was that there is no such thing as a ‘green’ or ‘not green’ job and a broader view is needed.
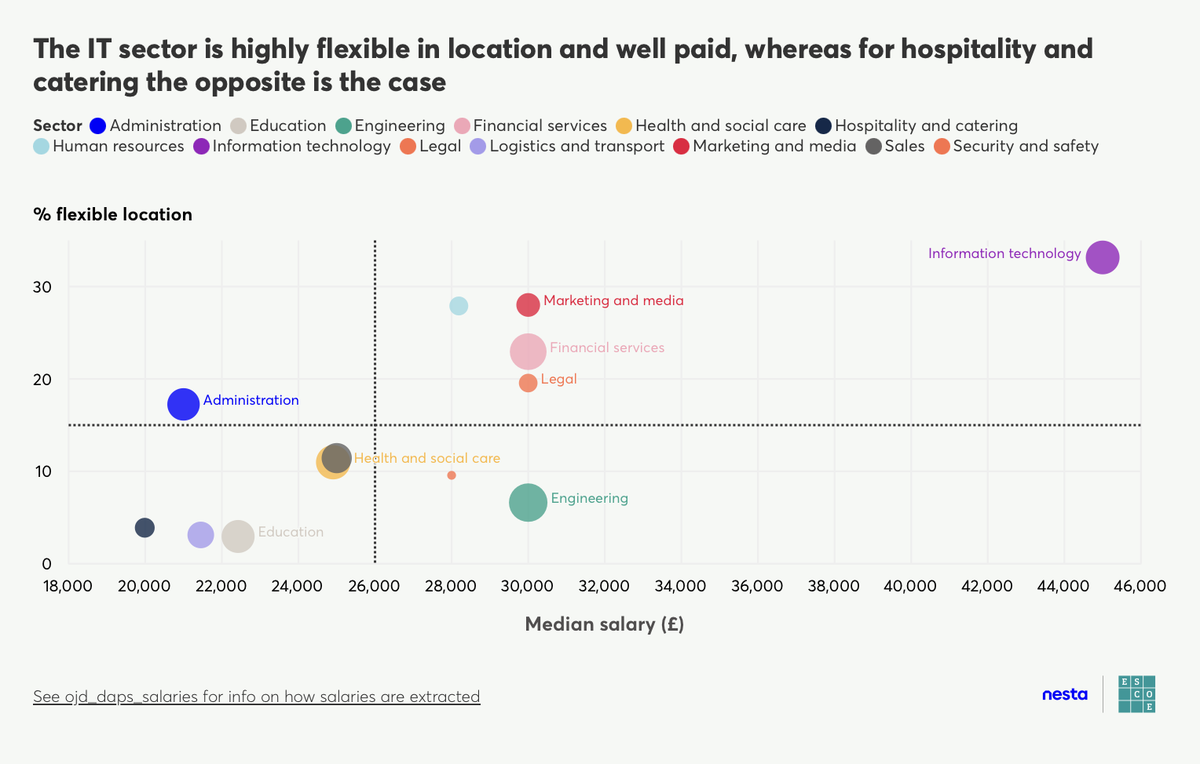
One of our last labour market projects kicked off in 2024, in which we looked at identifying the drivers of job quality within job adverts. In this, we developed algorithms to look for the most common dimensions of job quality listed in job adverts. We found that the majority of adverts (58%) mention pay and compensation, while only 18% mention career development. This work also allowed us to compare sectors in terms of job quality, potentially giving us some insight into why people might leave jobs or find others more attractive. This is particularly pertinent in the early-years childcare sector, where there is a need to retain staff to match increasing demand for childcare. View the data visualisation in more detail.
Back in 2020, we made the decision to start scraping our own job adverts rather than paying for them. We spent around six months setting up this algorithm and since then it’s been collecting job adverts really smoothly. Since this has been running so smoothly for five years, we almost wonder whether we spent too long over engineering this algorithm and something more basic could have been done even more quickly.
Having our own dataset of job adverts has meant we have a lot of freedom to use it in our work, and it’s been a great asset for experimenting with new project ideas or methodologies without having to commit to high data costs.
Having a large dataset of text, unstandardised fields, geographic and temporal fields, as well as a wealth of labour market research questions to explore - have made for a perfect hot bed for developing our data science skillset over the years.
In recent years, extracting information from our dataset of job adverts has allowed us to learn and refine our data science skills in name entity recognition, machine learning, large language models, semantic mapping, clustering, data cleaning, data visualisation and dashboard design. We’ve also had to enhance our data engineering skills in creating python packages, scaling and optimising code, training and hosting models on cloud services, and scraping and structuring HTML. All this was made possible by the novelty of what we were doing, in which we had to have time factored into our project timelines to test new methods or tools. It also greatly helped that our project teams were genuinely excited and collaborative about using new approaches to create the best solutions.
Releasing our skills extractor algorithm openly and finding that people were using it gave us a lot of inspiration for improving it, as well as helping us learn for future projects. It’s given us a new found appreciation for the open source coding community out there.
Our team mostly works on Mac laptops, so when a Windows user alerted us to the fact that the package wasn’t compatible with Windows computers it helped us to ensure cross-platform functionality for staff. Similarly, the issues of python versions and dependencies were prompted by external users for us to fix. This process helped us realise the need to switch to using Poetry, which has made the package much easier to develop.
Other issues alerted us to bugs, or the fact that many people were finding it hard to download our models necessary for the package to use - prompting us to host it on HuggingFace instead of Amazon Web Service S3.
Having users also inspired and motivated us to try to make the package more streamlined, optimal and usable. Last year we did a huge refactor of the package to help with this and the process was really great in helping us think about package design for future projects. For example, keeping the training of models in different repositories than the inference, or taking the time to make documentation as clear as possible.
We hope our work can continue to be useful to the labour market research community. As highlighted across this project update, we have left behind a whole host of various reports, data visualisations and code repositories.
We have datasets of various aggregations of our job advert data available to download. These give data on common skills, salaries, industries, locations, green measures, similar occupations and yearly data aggregated per occupation, industry and region. Click on the following buttons to download the data.
Please also get in touch with if you would be interested in our full dataset of job adverts!
Our work on extracting information from job adverts can be found across the following Github repositories:
The open-source code behind our Green Jobs Explorer - code which extracts green skills, and maps SOC and SIC to occupational and industrial green measures respectively.

Each of our projects on the labour market was funded externally, and the team are extremely grateful for support from the following organisations and groups: the Department of Education, the Gatsby Foundation, the JP Morgan Chase Foundation, the Economic and Social Research Council, the Economic Statistics Centre of Excellence, the Productivity Insights Network, SkillsFuture Singapore and the Productive and Inclusive Net Zero (PRINZ) Research Project.
We’d also like to acknowledge all the hard work of Nesta staff past and present involved in labour market research at Nesta, including Cath Sleeman, Jyldyz Djumalieva, Antonio Lima, Alex Bishop, Joel Klinger, Jack Vines, Adeola Otubusen, George Richardson, Karlis Kanders, Juan Mateos-Garcia, Genna Barnett, India Kerle, Liz Gallagher, Zayn Meghji, Emily Bicks, Lauren Orso, Suraj Vadgama, Andrew Sissons, Iman Muse, Mallory Durran, Rosie Oxbury, Tiff Holmgren, and Clare Brennan.




