Failing fast with AI: lessons from building Nesta’s agentic Signal Scout
 www.nesta.org.uk/project-updates/failing-fast-with-ai-lessons-from-building-nestas-agentic-signal-scout/
www.nesta.org.uk/project-updates/failing-fast-with-ai-lessons-from-building-nestas-agentic-signal-scout/
www.nesta.org.uk/project-updates/failing-fast-with-ai-lessons-from-building-nestas-agentic-signal-scout/
www.nesta.org.uk/project-updates/failing-fast-with-ai-lessons-from-building-nestas-agentic-signal-scout/

This project update shares developments in our work on automated horizon scanning, demonstrating how we changed our approach to delivering insights on emerging trends related to Nesta’s missions. As the needs of internal users shifted, a willingness to experiment, including with new technologies like agentic AI, has been key to this evolution.
In 2023, Nesta’s Mission Discovery started work on a dynamic automated horizon scanning product called Mission Radar. The premise was that artificial intelligence would enable us to continuously parse large volumes of data from various innovation-related sources, like Crunchbase for venture funding, UKRI’s Gateway to Research for research funding and Hansard for policy developments. This built on our previous data-driven horizon scanning undertaken through our Innovation Sweet Spots methodology. By casting the net wide and using automated techniques to filter for relevant signals, we could stay abreast of the latest innovation trends in Nesta’s mission areas of sustainability, health, and education.
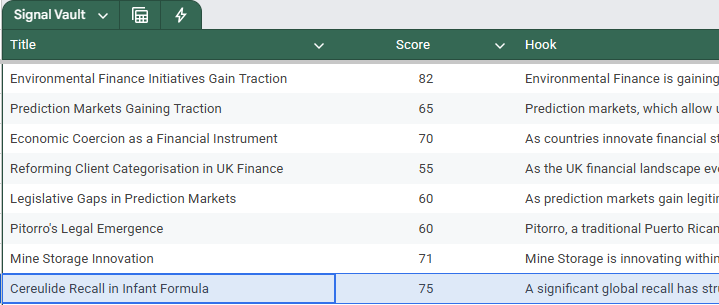
Mission Radar consisted of checking our data sources for key words relevant to Nesta’s missions on a recurring basis. Large language models (LLMs) reviewed the identified companies, research projects, or parliamentary speeches to verify their relevance to Nesta’s missions. These LLMs then synthesised information about the companies, projects, and debates into concise snippets, which were broadcast to users in a dedicated Slack channel (see Figure 1).

Figure 1: Screenshot of automated horizon scanning Slack channel
This approach was developed in response to clear user demand within Nesta for a tool that could convert a large number of signals into an easily digestible format. The core features were designed based on user research, with updates made according to regular feedback. Our initial primary user base, Nesta’s investments team, reported positive outcomes, noting a significant decrease in time spent manually searching datasets for relevant developments. Encouraged by this, we engaged other teams within Nesta, such as policy, that we thought might similarly benefit.
However, as often occurs, internal priorities shifted. The needs of our users changed, so the Slack channel stopped being so useful. It was time to rethink our approach.
Going back to the drawing board meant revisiting the core user problem. We identified a disconnect in our user journey: while the tool was originally built for the investments team (focusing on investment signals), we attempted to scale it to the policy and ventures teams (focusing on research funding and parliamentary signals). User interviews revealed that unlike the investments team, for whom an existing research process was simply automated, policy and ventures colleagues’ research was more exploratory and varied, and they often lacked the bandwidth to monitor a high-frequency stream of raw signals.
Faced with information overload, sifting through vast amounts of data to find relevant insights is a significant challenge. The previous automated Slack bot was a good starting point, but policy users said it was ‘noisy’ and lacked the personalisation needed to be useful. We realised the success of any new tool hinged on its ability to provide filtered, actionable insights that easily integrate into the work of people with limited time.
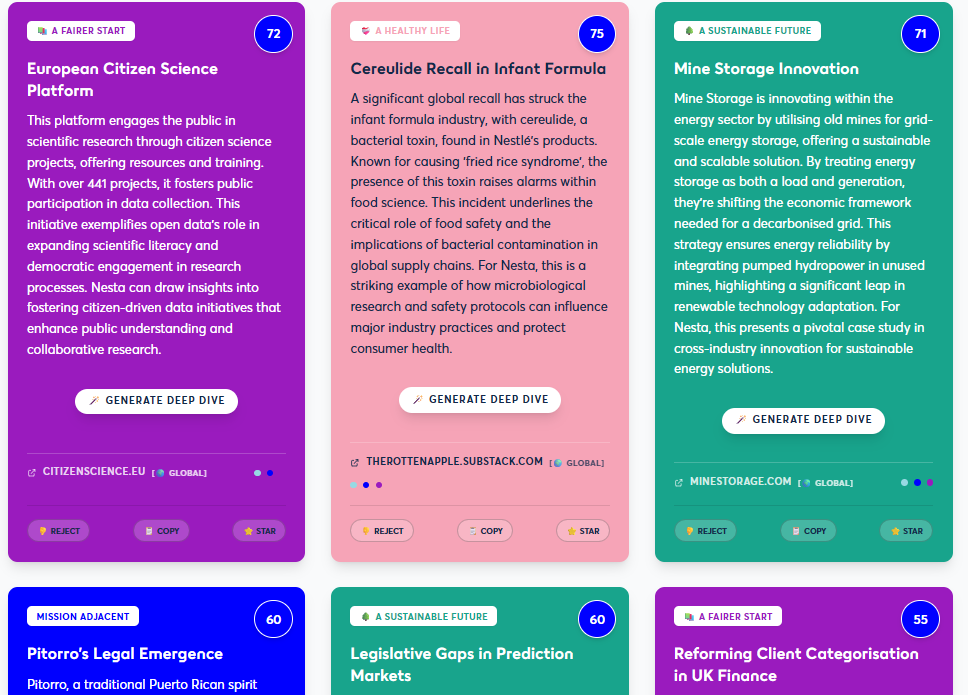
This led to a strategic pivot. We realised that the most effective way to deploy this technology was to centralise it. The primary user shifted from the ventures and policy teams to the Mission Discovery team, which had the capacity to use the tool as a research engine. We would use the agent to automate the heavy lifting of web trawling, acting as the “human-in-the loop" to curate and share the most relevant, high-impact signals with stakeholders.
With the user and user problem redefined, we looked for a technological solution that could outperform the previous keyword-based Slack bot. We believed agentic AI was the answer.
Traditional signal detection is highly manual, resource-intensive, and limited by time. Agentic AI systems capable of autonomous web browsing, complex reasoning, and structured data extraction-offered a way to continuously monitor vast amounts of unstructured web data, such as news, research papers, policy changes.
We hypothesised that an AI agent could filter out the noise, identify emerging trends relevant to Nesta’s missions, and format these insights into actionable intelligence. Shifting from using automated keyword search to agentic AI would also provide the flexibility to address changing organisational priorities while requiring fewer resources.
We conducted a series of experiments on platforms with agentic capabilities to test this hypothesis. The success criteria was simple: the agentic AI must be able to find, accurately format, and output emerging signals deemed novel enough to be shared with colleagues at Nesta. We experimented with three ways of achieving this goal.
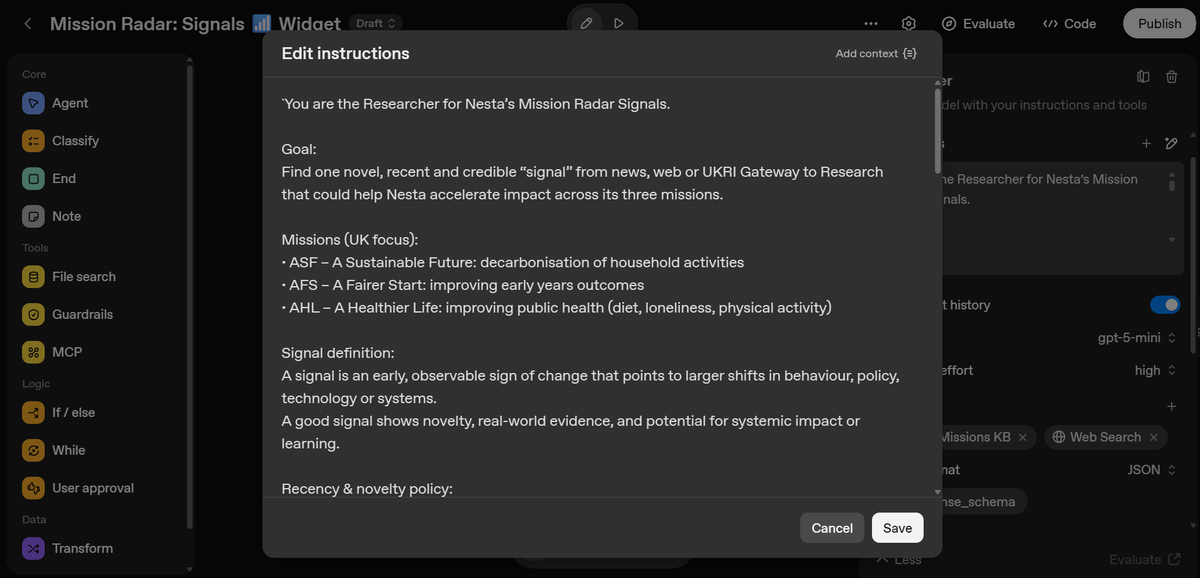
We started with a rapid prototype using OpenAI Agent Builder, a drag-and-drop tool that allowed us to link different AI tasks together like LEGO bricks, without needing to write complex code. We configured a custom workflow with specific prompt instructions detailing what a ‘signal’ looked like (see Figure 2). We gave the agent access to Nesta’s mission context via a file search tool, and enabled web browsing. In essence, we gave the AI a stack of Nesta’s strategy documents so it understood our thematic focus and told it exactly what kind of information and websites to target.
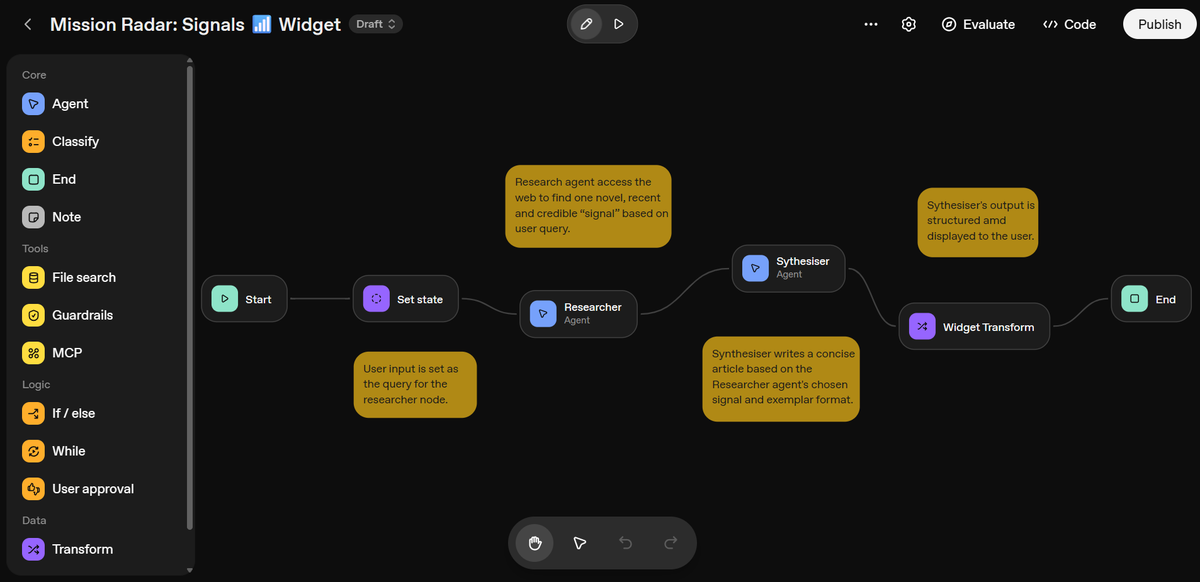
We instructed the ’researcher’ AI to interpret a user query, run targeted web searches, and score results. A ‘synthesiser’ AI was then configured to write a user-friendly article about the top signal found. The relationship between these two distinct "personalities" within the agent is visualised in Figure 3.
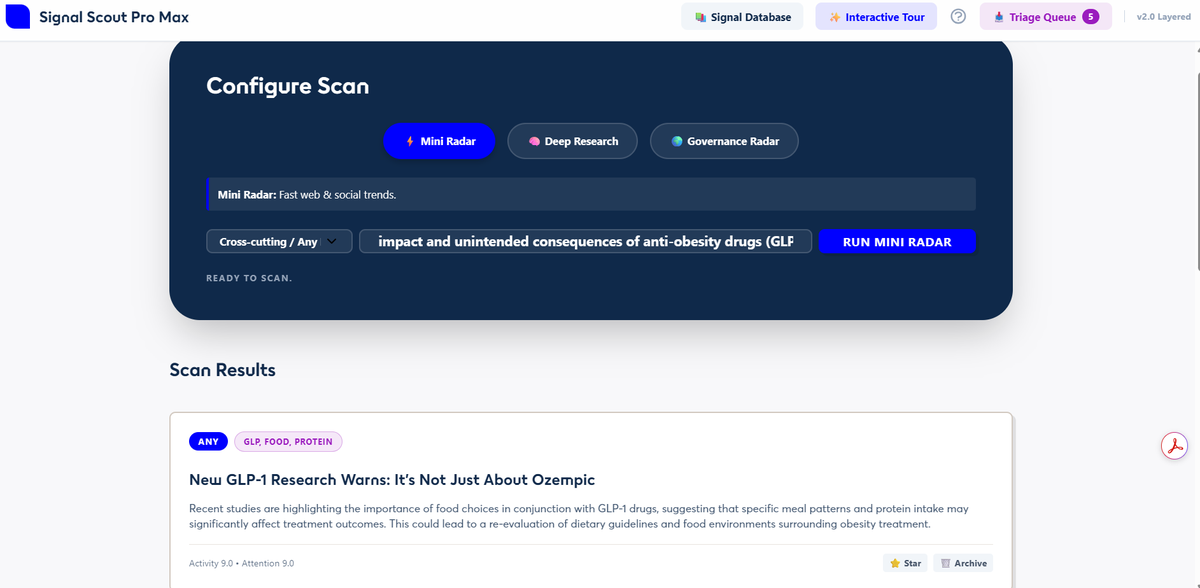
From the user’s perspective, this meant you could type a simple prompt like, “Find a signal related to heat pumps,” and the AI would return a short summary of a recent development and its relevance to Nesta (Figure 4).
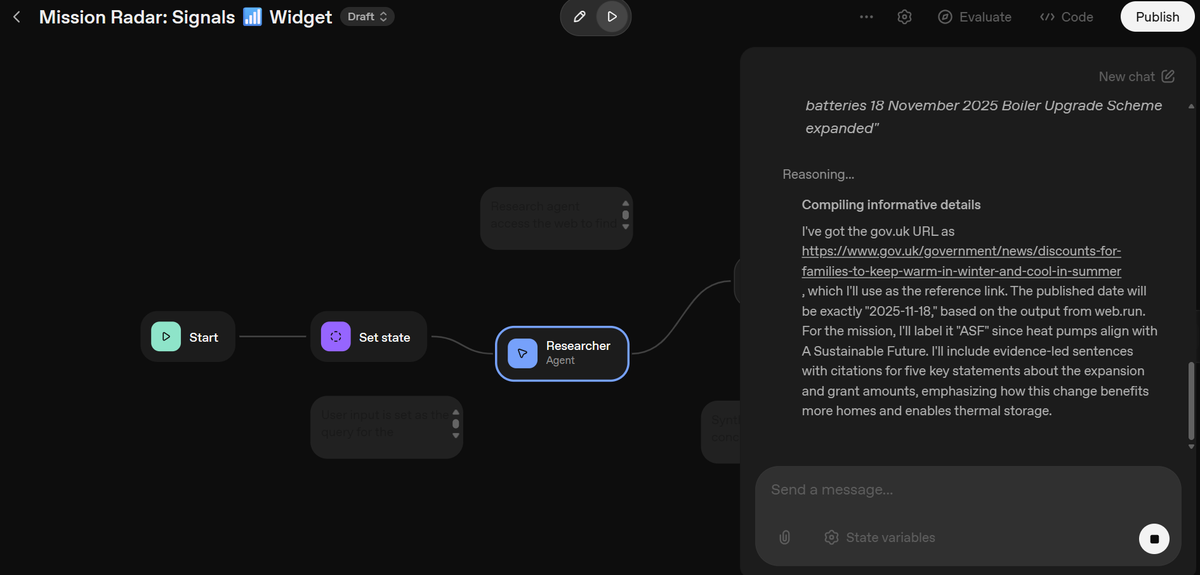
Figure 4: OpenAI agent processing a user query in a chat window
The AI proved capable of identifying and synthesising relevant innovation, technically meeting our success criteria. However, the workflow had significant limitations. The agent struggled to perform deep browsing (only reading search snippets rather than full pages), and lacked persistent data storage-outputs vanished when the chat window closed. We learned that we needed custom architecture to control the data pipeline.
We abandoned the native OpenAI chat interface to address the lack of data persistence and control. We built our own custom application suite to bridge the engineering gap-moving from a no-code prototype to a robust software application. To do this rapidly, we utilised Codex, an AI coding tool, which acted as our pair programmer to quickly generate the necessary code.
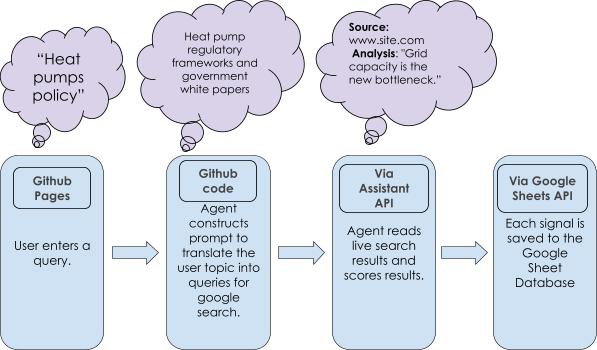
With Codex's assistance, we built a frontend hosted on GitHub Pages (Figure 4) and a custom live service backend deployed on Render. The backend automatically piped the agent's outputs directly into a Google Sheets database (Figure 5). This ensured we had a persistent, automatic spreadsheet where all the AI’s findings were saved and stored.
While the infrastructure was decoupled, separating our user interface from the database, this iteration still relied heavily on the OpenAI Assistants API to perform web searches (Figure 6). This meant the core logic and state of the agent still lived on OpenAI's servers, which presented three issues.
Because we were passing user inputs directly into an assistant that "remembered" conversation history, the system was highly vulnerable. A user could enter a poorly phrased question or malicious instruction that confused the AI, causing it to override core instructions and return incorrect results.
We couldn't properly track changes to the agent's behaviour because its "brain" lived in an external dashboard rather than our codebase.
OpenAI announced the retirement of the API version used by our assistant. This meant the tool was built on borrowed time; it would break once OpenAI turned off the API.
Figure 8: Github prompt instructions sent to Assistant API
When this agent worked, it met our success criteria by piping relevant signals into our spreadsheet-a significant improvement over experiment one (Figure 7). However, the underlying foundation was too unpredictable for a long-term product. The lack of version control meant we couldn't fix a mistake and guarantee it stayed fixed, while the looming API retirement meant we were building on shifting sands.
Due to these issues in experiment two, we executed a major architectural migration: we shifted entirely to a "GitHub-only" code approach. We stripped out the assistants’API entirely and moved to direct LLM calls (chat completions).
The entire "brain" of the agent-all the complex prompt engineering, safety rails, and logic-was moved explicitly into our GitHub repository. This gave us absolute version control, immunised the system against basic prompt injection, and removed our dependency on a retiring API layer.
With this secure, code-driven foundation, we improved the agent’s analytical rigor. We implemented multi-step reasoning natively in our Python backend. This forced the AI to assign quantitative scores based on specific rubrics and extracted implications before writing to the database.
Think of this like upgrading from an intern to a senior analyst. Instead of just asking the AI to "read this article and give me a summary," we gave it a strict grading rubric. It had to explicitly justify how impactful, new, and credible a signal was before it was allowed to save it to our database. For the user, this meant the data we got back wasn't just a block of text; it was highly structured, deeply analysed intelligence.
Agentic AI is exceptionally powerful when constrained by highly specific, multi-dimensional rubrics hardcoded into a secure backend. By forcing the LLM to justify its scores and break its analysis down into strict format, the quality of the outputs skyrocketed. This final iteration satisfied our success criteria: the agent now acts as a secure, autonomous scout that gathers highly structured intelligence for the discovery team to review (Figure 8).
The development of the Nesta Signal Scout was not a straight line, but an exercise in hypothesis-driven development and assumption testing-“test and learn”. By embracing an agile mindset, our most valuable insights came from our missteps.
Our initial assumption was that a tool that worked well for the investments team would naturally translate to the policy and ventures teams. We made contact with reality quickly by returning to our users. We learned that stakeholders needed curated insights, not a raw firehose of data. Focusing on the user’s actual problem - not the technical solution - allowed us to fail fast and pivot to making the discovery team the primary user.
Rather than spending months over-engineering a monolithic backend from day one, we iteratively tested and learned our way to the right architecture.
Our agentic AI horizon scanning tool (“Signal Scout”) enables us to continuously scan for signals and trends related to Nesta’s missions. It also enables us to launch quick targeted scans in new areas of exploration. We will iteratively refine its scope and delivery based on internal feedback to ensure maximum relevance. While Signal Scout is a powerful addition to our toolkit, we remain mindful of LLM biases and prompt-based blind spots; it is designed to augment our human-led foresight, not replace it.